| text | token_short | token_long | p_short | p_long | JS |
|---|---|---|---|---|---|
| Loading... (need help?) |
A catalog of several million tasks Pythia can do
We’re sharing datasets that we hope will be useful for language model interpretability.
- Token-bigram and token-trigram prediction: a dataset of n-gram statistics from The Pile [1] including tables of one and two token prompts with their most likely completions. One of the simplest “tasks” for a language model is bigram completion.
- for example, during training, 99.8% of the time the model sees
" telome", the correct next token is"res".
- for example, during training, 99.8% of the time the model sees
- First token deletion: a dataset constructed by differencing the outputs of Pythia-2.8B [2] between four and five token prompts. This method highlights tokens that are extremely predictive in context.
- for example, when prompted with
", or common table", the model predicts" expression"(CTE) with probability 0.37. But, if we prompt with" chloride, or common table", then the model predicts" salt"with probability 0.99.
- for example, when prompted with
The data
In following sections we will give details on the construction and statistics of these datasets. Before continuing, we share some interactive data previews:
- Deletion: the first 25000 rows of pile_scan_4.
- Bigrams: the entirety of pile_top_bigrams, which contains bigrams with suffix probability greater than 50%.
- Trigrams: the first 25000 rows of pile_top_trigrams, which contains trigrams with suffix probability greater than 50% and count greater than 1000.
The columns of the table below:
text: the two prompts provided. The additional token of backwards context is surrounded by square brackets. The example in the introduction would be written"[_chloride],_or_common_table".token_short: the most likely next token predicted by Pythia-2.8B for the four token prompt.token_long: the most likely next token predicted by Pythia-2.8B for the five token prompt.p_short: the probability Pythia-2.8B assigns totoken_short.p_long: the probability Pythia-2.8B assigns totoken_long.JS: the Jensen-Shannon divergence between the model’s output distributions for the four and five token prompts.
Note:
- in the table, spaces are replaced with underscores for clarity.
- there are offensive tokens in the dataset. We have not removed them.
The table below shows bigram completions in The Pile sorted by the frequency of occurence of the prefix token:
token#: the tokens of the bigram.sum_count: the number of times the first token of the bigram occurs in The Pile.frac_max: the fraction of first token appearances that are followed by the most common bigram completion. For example, 50.3% of the time the model sees" need", the correct next token is" to".p_2.8b: the probability Pythia-2.8B assigns to the most likely completion token when prompted with just the prefix token.
Note:
- in the table, spaces are replaced with underscores for clarity.
- there are offensive tokens in the dataset. We have not removed them.
| token0 | token1 | sum_count | frac_max | p_2.8b |
|---|---|---|---|---|
| Loading... (need help?) |
The table below shows trigram completions in The Pile sorted by the frequency of occurence of the prefix bigram:
token#: the tokens of the trigram.sum_count: the number of times the prefix bigram occurs in The Pile.frac_max: the fraction of bigram appearances that are followed by the most common third token. For example, when prompted with the tokens["://", "www"], 99.4% of the time, the next token is".".p_2.8b: the probability Pythia-2.8B assigns to the most likely completion token when prompted with the prefix bigram.
Note:
- in the table, spaces are replaced with underscores for clarity.
- there are offensive tokens in the dataset. We have not removed them.
| token0 | token1 | token2 | sum_count | frac_max | p_2.8b |
|---|---|---|---|---|---|
| Loading... (need help?) |
Bigrams and Trigrams
To construct bigram and trigram statistics, we process the entire deduplicated Pile.
We share six datasets on Huggingface. Descriptions of the datasets are available in the linked dataset cards:
- pile_bigrams: Raw bigram statistics:
- 479 million unique bigrams.
- pile_bigram_prefixes: All bigram prefixes with their most common completion token.
- 50,054 unique bigram prefixes (one row for each unique token).
- pile_top_bigrams: Those bigram prefixes for which the most common completion has > 50% probability. We add Pythia’s probability of the most frequent completion for each Pythia model.
- 3,448 such bigram prefixes. All of these are available to browse on this page above.
- pile_trigrams: Raw trigram statistics.
- 9.9 billion unique trigrams.
- pile_trigram_prefixes: All trigram prefixes with their most common completion token.
- 479 million unique trigram prefixes (equivalent to bigrams).
- pile_top_trigrams: Those trigram prefixes for which the most common completion has > 50% probability and where the prefix occurs more than 1000 times in The Pile. We add Pythia’s probability of the most frequent completion for each Pythia model.
- 1,542,074 such trigram prefixes. The top 25k are available to browse on this page above.
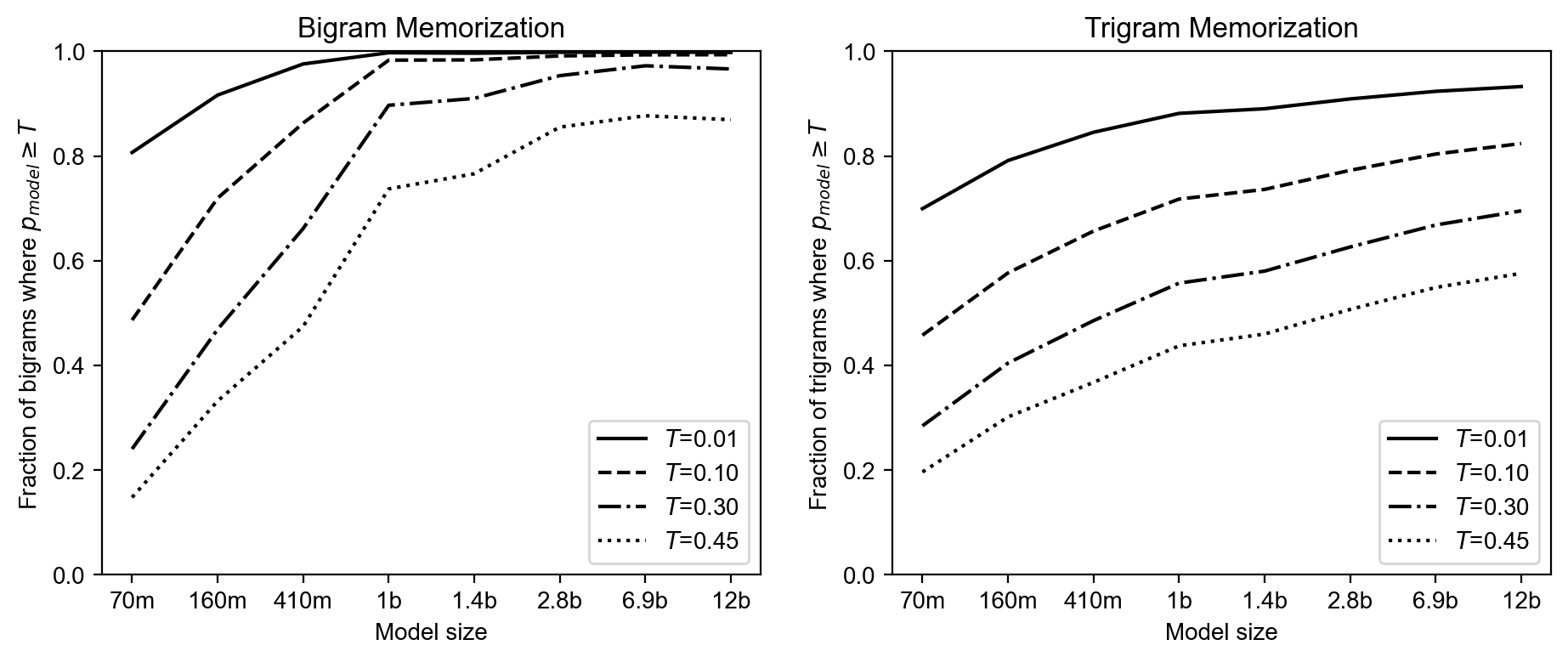
Below, we show the memorization rates for each Pythia model on the pile_top_bigrams and pile_top_trigrams datasets. Since these datasets have been filtered to cases where the most common completion has > 50% probability, we hope to see models predicting the most common completion with high probability. Larger models perform better, but even Pythia-12B is miscalibrated on 20% of the bigrams and 45% of the trigrams when we ask for prediction of \(p \geq 0.45\).
Usage notes:
- Because the byte-pair encoding tokenizer from GPT-NeoX [3] was trained on The Pile, there are no single tokens in The Pile where the subsequent token is 100% predictable. However, there are many trigrams that are 100% predictable.
- Some whitespace token bigrams will also tokenize as a single token. For example, with the GPT-NeoX tokenizer,
"\n\n\t\t"is a token,"\t"is a token and"\n\n\t\t\t"is also token. It’s important to be aware of this when automatically tokenizing many prompts because almost all concatenated bigrams will tokenize to two tokens but a few whitespace-related bigrams will tokenize to one token. We have not removed these bigrams from the dataset. This white space tokenization is discussed in Appendix F of [3].
First token deletion
If deleting the first token of a prompt gives a dramatically different output from a language model, then something interpretable may be going on. For example, consider the prompt, ", or common table". Given this prompt, Pythia-2.8B predicts the most likely next token is " expression" with probability 0.37. Next, we provide an additional token of context in the backwards directions with the prompt, " chloride, or common table". Then, the model correctly predicts " salt" with probability 0.99.
We scan through the pre-training corpus \({t_0,...,t_N}\) and compare the output of the model on pairs of prompts:
- \(p_0 = [t_i, ... t_{i + n}]\) is a contiguous \(n\)-token prompt from the pre-training corpus.
- \(p_1 = [t_{i-1}, t_i, ... t_{i + n}]\) is an \((n+1)\)-token prompt where an additional token, \(t_{i-1}\) has been added in the backwards direction in the text.
Suppose \(M(p)\) is a model than outputs a probability distribution over output tokens. When \(M(p_1)\) differs substantially from \(M(p_0)\), we capture the two prompts as a “task”. To be more precise, we accept the task if:
\[\mathrm{JSD}(M(p_0), M(p_1)) > 0.5 ~~~~\mathrm{and}~~~~ \max_{i} M(p_1)_i > 0.5\]
where JSD is the Jensen-Shannon Divergence. This criterion means that we focus on tasks for which the addition of \(t_{i-1}\) to the prompt has a large influence and results in a confident prediction. Note that the true next token \(t_{i + n + 1}\) does not factor into these criteria and therefore the correctness of the model’s predictions does not affect whether we consider the model to be “completing a task”.
We share 1,874,497 tasks produced by prompt scanning with Pythia-2.8B for every sliding 5-token prompt in the first 112.5M tokens of the Pile. The dataset is available on Huggingface: pile_scan_4
n = 4for this dataset, meaning that we provide an initial 4-token prompt and then add a single token to the beginning of the prompt for the second 5-token prompt.- for 1,067,168 tasks, the most likely token is the same for both prompts. Often the model will become much more confident of its initial prediction after seeing the additional token.
- for 807,329 tasks, the predicted tokens are different.
Scaling this method to the entire Pile would probably result in a several hundred million such tasks.
GitHub
The code to reproduce the datasets here is available at: https://github.com/Confirm-Solutions/catalog
References
[1]
L. Gao et al., “The Pile: An 800GB dataset of diverse text for language modeling,” arXiv preprint arXiv:2101.00027, 2020.
[2]
S. Biderman et al., “Pythia: A suite for analyzing large language models across training and scaling.” 2023. Available: https://arxiv.org/abs/2304.01373
[3]
S. Black et al., “GPT-NeoX-20B: An open-source autoregressive language model,” in Proceedings of BigScience episode #5 – workshop on challenges & perspectives in creating large language models, virtual+Dublin: Association for Computational Linguistics, May 2022, pp. 95–136. doi: 10.18653/v1/2022.bigscience-1.9.
Citation
BibTeX citation:
@online{thompson2023,
author = {Thompson, T. Ben and Sklar, Michael},
title = {A Catalog of Several Million Tasks {Pythia} Can Do},
date = {2023-06-25},
url = {https://confirmlabs.org/posts/catalog.html},
langid = {en}
}
For attribution, please cite this work as:
T.
B. Thompson and M. Sklar, “A catalog of several million tasks
Pythia can do,” Jun. 25, 2023. https://confirmlabs.org/posts/catalog.html